installing archlinux
For installing archlinux it was enough to follow the
instructions.
For booting archlinux I chose, in the BIOS,
efi boot.
I formatted the hard disk with a gpt label
and installed GRUB on a partition of 500Mib
(looks too big at first sight, but actually GRUB occupies 220Mib).
After this, booting was smooth.
The only original part was that I decided to keep the pacman cache
on the USB stick (where the live system boots from).
To do this, when burning the archlinux image (using rufus)
I chose a high value for
persistent partition size;
this left a lot of free space on the stick;
on that free space I created (using fdisk) a second (ext4) partition.
In the live system, I mounted this second partition on /mnt/cache.
Then I specified in /etc/pacman.conf the cache directory
/mnt/cache/pacman/pkg/ and added the -c option to
the pacstrap command in order to use
the local cache rather than the cache on the installed system.
This way, when installing archlinux on the first machine the cache gets populated
and when installing on subsequent machines the package files are already in the cache.
This saves time and bandwidth.
As arguments to pacstrap, include all packages needed for a minimally
functional system, like nano, grub, efibootmgr,
intel-ucode, sudo, openssh.
configuring the network
Configuring the network was not trivial.
I chose to use systemd_networkd and systemd_resolved
as network managers;
they are included in the systemd package so they are installed by default.
Each machine has several ethernet ports;
on the eno1 links to a plug in the wall and to the outside world,
eno2 links to a switch and provides connectivity to the local network
of
I started by installing archlinux on the
alpha_nodearchlinux system, we need access to the internet :
ip address add your.machine.s.IP /24 broadcast + dev eno1
ip route add default via your.gateway.s.IP dev eno1/etc/resolv.confnameserver 1.1.1.1 # or some other server Then, in the installed system (after arch-chroot), create
/etc/systemd/network/20-wired-outside.network[Match]
Name=eno1
[Link]
RequiredForOnline=routable
[Network]
DHCP=yes
IPv4Forward=yes
[DHCPv4]
ClientIdentifier=mac If the DHCP service on your network does not exist or does not work properly,
you can use a fixed IP number instead:
/etc/systemd/network/20-wired-outside.network[Match]
Name=eno1
[Link]
RequiredForOnline=routable
[Network]
Address=your.network.address .ip_number /24
Gateway=your.network.address .1
DNS=1.1.1.1 # or some other server
IPv4Forward=yes For eno2, I created
/etc/systemd/network/20-wired-local.network[Match]
Name=eno2
[Network]
Address=192.168.1.1/24
IPv4Forward=yes If you want root to be able to login through ssh, add
/etc/ssh/sshd_configPermitRootLogin yes Note the name of the file : sshd_config, not ssh_config !
Beware, this opens the door to cyberattacks; remove this line as soon as you
implement a different way to login remotely as administrator;
until then, choose a strong password for root.
That different way to login remotely could be creating a regular user
and adding it to the wheel group,
then use sudo to gain super-user privileges.
In order for NAT forwarding.
Create
/etc/sysctl.d/30-ipforward.confnet.ipv4.ip_forward=1/etc/systemd/system/nat.service[Unit]
Description=NAT configuration for gateway
After=network.target
[Service]
Type=oneshot
ExecStart=/usr/bin/iptables -t nat -A POSTROUTING -o eno1 -j MASQUERADE
ExecStart=/usr/bin/iptables -A FORWARD -i eno2 -o eno1 -j ACCEPT
ExecStart=/usr/bin/iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target Then, enable the services (they will be effectively started after reboot) :
systemctl enable systemd-networkd
systemctl enable systemd-resolved
systemctl enable nat
systemctl enable sshd Replace enableenable --nowchroot).
Commands like systemctl statussystemctl status
journalctl -xe
On each eno2.
On the live archlinux system, we need access to the internet
(using
ip address add 192.168.1.beta /24 broadcast + dev eno2 # beta = 2, 3, 4, ...
ip route add default via 192.168.1.1 dev eno2/etc/resolv.confnameserver 1.1.1.1 # or some other server Then, in the installed system (after arch-chroot),
/etc/systemd/network/20-wired-local.network[Match]
Name=eno2
[Network]
Address=192.168.1.beta /24 # beta = 2, 3, 4, ...
Gateway=192.168.1.1
DNS=1.1.1.1 # or some other server If you want root to be able to login through ssh,
follow the steps described above for the
Then, enable the services (they will be effectively started after reboot) :
systemctl enable systemd-networkd
systemctl enable systemd-resolved
systemctl enable sshd Replace enableenable --nowchroot).
NTP (network time protocol)
Some applications (make for example) rely on the timestamp of
files in order to work correctly.
Thus, it is important that the machines composing the cluster have the clocks
synchronized (otherwise, sharing file through NFS could stir up trouble).
NTP is a good solution for that.
Actually, NTP does more than we need.
It synchronizes the clock of your machine with a universal time provided by timeservers
scattered across the world, and it does it with a very high precision.
What matters for us is sychronization between our machines only.
Anyway, NTP does the job.
Although the live archlinux comes with systemd-timesyncd enabled,
on the installed archlinux we must choose and install a service providing
NTP.
On the ntp;
it provides a client which gets the time from an exterior server
and also a server, used by the
pacman -Syu ntp
systemctl enable --now ntpd We must also ensure the ntpd service waits for the systemd-networkd
service at boot. Create
/etc/systemd/system/ntpd.service.d/wait-for-network.conf[Unit]
After=network-online.target
Wants=network-online.target The command systemctl status ntpdkernel reports TIME_ERROR: 0x41:
Clock Unsynchronized;
looks like this message can be safely ingored.
Check with ntpq -p
On the systemd-timesyncd
which only provides a client.
It gets the time from the
/etc/systemd/timesyncd.confNTP=alpha_node systemctl enable --now systemd-timesyncd systemd-timesyncd handles graciously network failures, so the next step
is optional : create
/etc/systemd/system/systemd-timesyncd.service.d/wait-for-network.conf[Unit]
After=network-online.target
Wants=network-online.target Somewhat misleadingly, the command timedatectl
statusNTP service: active if we use systemd-timesyncd but
answers NTP service: inactive if we use ntp.
disk partitions
Each machine has a 895Gib disk.
I have reserved 200Gib for the operating system and 15Gib for a swap partition.
We intend to use /nfs-home on one machine as home directory;
it will be available to other machines through NFS.
I have chosen the
/nfs-home.
So, on the /nfs-home on a 300Gib partition;
/sci-data is mounted on a 380Gib partition.
On each /nfs-home directory from
NFS and
/sci-data is mounted on a local 680Gib partition.
See section "intended disk usage" below.
NFS (network file system)
Installing and configuring NFS was not that difficult.
On the server side (on the pacman -Syu nfs-utils/etc/exports.
I listed all
/etc/exports/nfs-home beta_node (rw) another_beta_node (rw) yet_another_one (rw) Then systemctl enable --now
nfsv4-server/nfs-home, e.g. by invoking
useradd-b or -d
(or edit /etc/default/useradd).
On the client side, pacman -Syu
nfs-utilsmkdir /nfs-homemount /nfs-home/nfs-home becomes invisible until umount
(as happens with any mount operation).
To mount /nfs-home through NFS automatically at boot time,
you should edit /etc/fstab.
I did not implement kerberos authentication.
One has to be careful about the user IDs.
If you have two users on different nodes with the same username but different IDs,
they will be unable to access their home directory through NFS.
See paragraph "user accounts".
intended disk usage
/nfs-home
through NFS, disk access will be rather slow on this directory.
Thus, users are encouraged to keep large files on local storage, under /sci-data.
A folder /sci-data/
exists for that purpose on all machines.
Configuration and preferences files should be kept in
/nfs-home/ of course;
this is useful for defining your preferences throughout the cluster.
pacman's cache
In order to save bandwidth and installation time, I want to share pacman's cache
among the computers composing the cluster.
During the initial installation of archlinux I kept the cache on the USB
stick, as explained in section "installing archlinux" above.
For normal updates, I share pacman's cache through NFS.
However, this is not a trivial process because the package files should be owned by
root and this is not compatible with NFS' philosophy
(I decided against specifying the no_root_squash option).
I use a "temporary" cache directory /nfs-home/cache, owned by a regular user.
Each update operation is initiated on the /var/cache/pacman/pkg.
Before calling pacman -Syu/var/cache/pacman/pkg; after the update has finished on the
/nfs-home/cache.
Old versions of package files in /var/cache/pacman/pkg are deleted
using the command paccache -rk1/nfs-home/cache to /var/cache/pacman/pkg,
ensuring that the copied files are owned by root.
We then perform the update; in theory, there is no need to download any package file.
After updating the /var/cache/pacman/pkg (which thus stays empty most of the time).
After all /nfs-home/cache is also emptied.
Of course all the above is not performed by hand; rather, it is done through a python script.
moving and copying files with different owner
While working on the script for moving around package files
(see section "pacman's cache" above), I have noticed something peculiar
about the commands mv and cp.
Suppose there is a file file-1.txt belonging to user-A.
Suppose another user, user-B, goes to that directory.
Suppose user-B has read and write permissions on the directory and on
file-1.txt.
If user-B issues the command mv file-1.txt
file-2.txtfile-2.txt will belong to
user-A. This is true independently of whether a file file-2.txt
exists (previously to the mv operation) or not.
If user-B issues the command cp file-1.txt
file-2.txtcp operation.
If a file file-2.txt existed previously and belonged to user-A,
then it will belong to the same user-A after the cp operation,
although with a new content.
If no file named file-2.txt existed previously, it will be created and will
belong to user-B.
I don't know if this is intended behaviour of command cp or is some sort of bug.
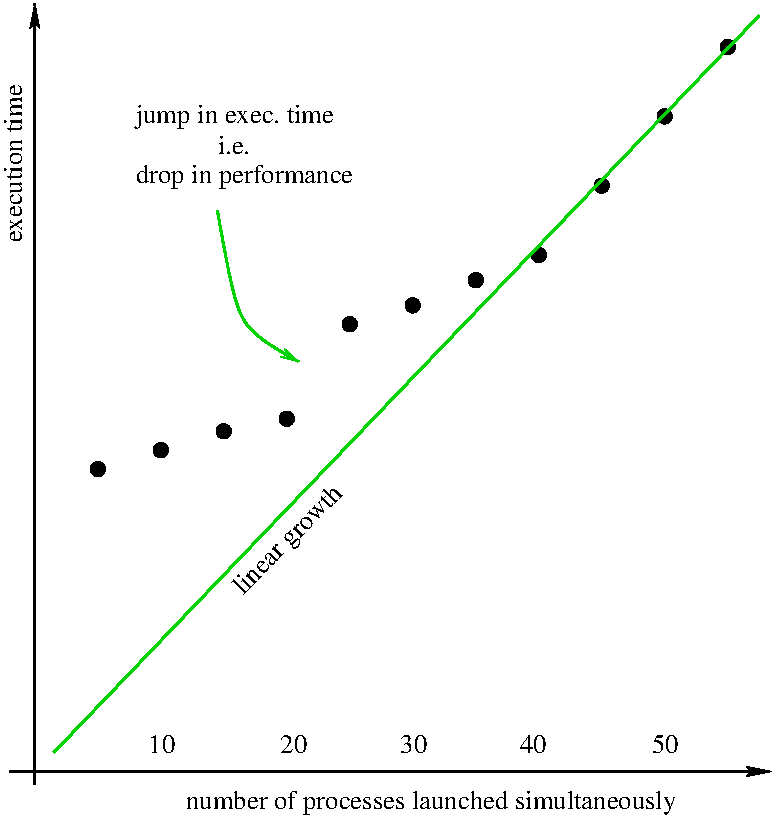
performance
Below is a graphic representation of the execution time for several identical (single-threaded) processes
launched simultaneously on one machine only.
We see a linear growth for more than 40 processes (serial behaviour).
We also see a drop in performance at 20 processes.
Recall that each machine has 20 cores, 40 threads.
So top).
user accounts
I wrote a script
for propagating user accounts and passwords across the nodes of the cluster.
It is written in python3 and uses
fabric.
cluster passwordpasswd command if you want different passwords on
different nodes, but why would you want that ?
Edit /etc/default/useradd if you want a default home directory different from
/home (in our case, /nfs-home).
The same script
can be used by the system administrator to add new users :
cluster add usercluster delete useruser, not the /nfs-home/
only on the NFS.
In contrast, the folder /sci-data/
is created on all machines.
If you are careful not to add/delete user accounts through other means than the above commands,
the user (and group) IDs will be the same across nodes (this is important since
/nfs-home is seen through NFS).
There are no quota.
periodic shutdown
The linux kernel is updated frequently, thus requiring frequent reboots,
which is rather annoying.