This page describes the configuration of a cluster of computers dedicated to scientific computing, with focus on parallel computation. The computers are hosted by Faculdade de Ciências da Universidade de Lisboa; they have been acquired by Centro de Matemática, Aplicações Fundamentais e Investigação Operacional (FCT project UID/MAT/04561/2020) and by Grupo de Física Matemática.
This document describes the steps I followed for configuring the cluster.
A large part of it is only relevant for system administrators.
Parts which are relevant for users of the cluster are highlighted by a
archlinux;
NTP (network time protocol) Some applications (make for example) rely on the correct timestamp of
files in order to work correctly.
Thus, it is important that the machines composing the cluster have the clocks
synchronized.
NTP is a good solution for that.
Actually, NTP does more than we need.
It synchronizes the clock of your machine with a universal time provided by timeservers
scattered across the world, and it does it with a very high precision.
What matters for us is sychronization between our machines only.
Anyway, NTP does the job.
The command apt install ntpntp
and starts the daemon.
On the pool
/etc/ntp.conf, before the Ubuntu servers;
thus, each client gets the time mainly from the local
Each machine has a 895Gib disk.
I have reserved 100Gib for the operating system and 15Gib for a swap partition.
Apparently the Ubuntu installation has already created an 8Gib swap
file, and I decided not to interfere with that, so the machines are using both.
Since we intend to mount /home through NFS, we only need
space for /home on one machine; I have chosen the
/home.
So, on the /home on a 300Gib partition;
/sci-data is mounted on a 480Gib partition.
On each /home directory from
NFS and
/sci-data is mounted on a local 780Gib partition.
See section "intended disk usage" below.
NFS (network file system) Installing and configuring NFS was not that difficult.
On the server side, apt install
nfs-kernel-server/etc/exports.
I inserted one line for each beta-node :
/home
I tried to list all five beta-nodes, like in
/home {
but it did not work.
The command systemctl start nfs-kernel-server.service
starts the daemon if it is not running; if it is already running, the command forces
the daemon to re-read the configuration files.
On the client side, apt install
nfs-commonmount /home/home becomes invisible until umount.
To mount /home through NFS automatically at boot time,
you should edit /etc/fstab.
I did not implement kerberos authentication.
One has to be careful about the user IDs.
If you have two users on different nodes with the same username but different IDs,
they will be unable to access their home directory through NFS.
See paragraph "user accounts".
/sci-data.
A folder /sci-data/
exists for that purpose on all machines.
Please clean up this folder after each job.
/home
through NFS, disk access will be rather slow on this directory.
Thus, the use of /home should be limited to relatively small files.
Configuration and preferences files should be kept in
/home/ of course;
this is useful for defining your preferences throughout the cluster.
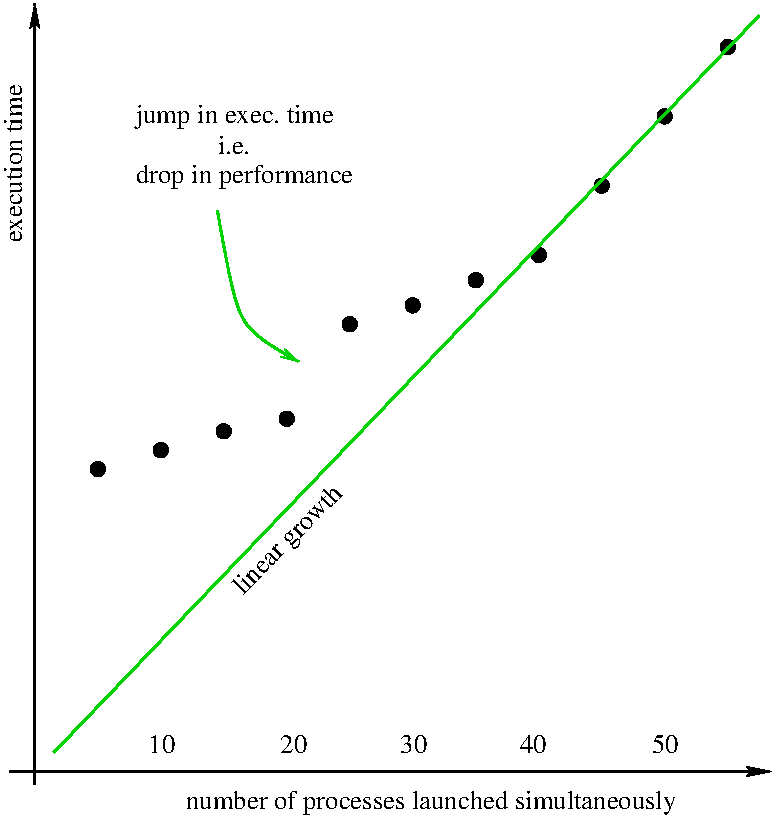
Below is a graphic representation of the execution time for several identical (single-threaded) processes
launched simultaneously on one machine only.
We see a linear growth for more than 40 processes (serial behaviour).
We also see a drop in performance at 20 processes.
Recall that each machine has 20 cores, 40 threads.
So top).
The default settings for file permissions are too loose.
To increase privacy, I added umask 0027/etc/login.defs and /etc/bash.bashrc.
(Variables in /etc/login.defs are relevant for useradd,
invoked by the script described in paragraph "user accounts".)
I wrote a script
for propagating user accounts and passwords across the nodes of the cluster.
It is written in python3 and uses
fabric.
cluster passwordpasswd command if you want different passwords on
different nodes, but why would you want that ?
The same script can be used by the system administrator to add new users :
cluster add usercluster delete useruser, not the /home/
only on the NFS.
In contrast, the folder /sci-data/
is created on all machines.
If you are careful not to add/delete user accounts through other means than the above commands,
the user (and group) IDs will be the same across nodes (this is important since
/home is seen through NFS).
There are no quota.
Ubuntu asks frequently for system restart, which is rather annoying.
ssh (sure shell connection) If I understand correctly, slurm does not need passwordless
ssh access between nodes; its daemon slurmd runs on each node
as root and launches processes on behalf of normal users.
So ssh configuration unchanged.
If a particular user feels they need passwordless ssh access between nodes,
they are free to configure it.
MUNGE (credential generator and manager) slurm uses MUNGE in order to make nodes in your cluster
trust each other.
MUNGE is easy to install,
just apt install munge/etc/munge/munge.key is generated if it does not exist.
You end up with several different key files on different machines, and the randomness
is weak.
You need a stronger encription which you achieve through create-munge-key
-f -r
It may sound silly, but propagating the key file is not an obvious task.
The key is secret so it should be propagated through an encripted channel like
ssh (or rather scp, I guess).
And it belongs to a user munge who cannot login, and it's write-protected
for everyone, and it's read-protected for any user other than munge.
And there is no root password
(Ubuntu does everything through sudo)
so you cannot open an ssh session as root.
And when you least expect, NFS gets in your way (the file should not be
transfered through NFS since NFS is not encripted).
Anyway, after you have the same key file on all nodes don't forget to
systemctl restart mungeNFS, start is not enough).
slurm (distributed job scheduler) By the way, there is another
slurm, a network load monitor.
You don't want that one, you want the
workload manager.
I used this simple slurm.conf example and this more complete slurm.conf example to guide myself.
Naturally, the first step is apt install
slurmctldapt
install slurmdslurm :
slurmctld is installed in the "controlling" computer where the users issue
requests for jobs; this could be the slurmctld handles these requests from users and forwards them to (one of the instances of)
slurmd according to criteria and to available resources.
slurmd is installed on each "computing node".
It waits for requests from slurmctld and fulfills them,
launching processes on behalf of the user who gave the original request.
MUNGE is used for autenticating users among nodes.
The "controlling" computer may be or may be not a "computing node";
in the former case, it will run both daemons.
Commands systemctl start slurmdsystemctl start slurmctldslurmd should run as root
while slurmctld should run as slurm user, we do not have to worry about that.
The apt installslurm user.
The log files in /var/log/slurm contain a lot of relevant information.
At first start the logs show many errors since slurm is trying to recover a previous,
non-existent, session. Next runs (restarts of the daemons) will not show again these errors.
There is no mail agent installed and slurm complains about this.
For the moment I am using slurm with no mail agent.
For getting the right hardware characteristics, you can use the command
slurmd -CCPUs = Boards *
SocketsPerBoard * CoresPerSocket *
ThreadsPerCore.
The configuration file /etc/slurm/slurm.conf (used by both daemons)
must be identical on all nodes.
slurmctld makes sure the files are identical using a hash value
so it will complain even about the slightest (whitespace) difference.
Also, the version of slurmctld must match exactly the version of
slurmd in all nodes.
It seems to me that slurm remembers a lot of information from previous sessions.
This may cause strange behaviours. In my case, nodes were considered "drained" because
of a mismatch in the memory size declared in slurm.conf.
Even after inserting the correct information in slurm.conf,
the error kept showing up. Commands like sinfo -lsmap -i 5s),
scontrol show node
scontrol update
nodename= state=resume
A nice tutorial about launching slurm jobs can be found
here.
srun
exec-fileslurm.
The file srun
command was issued.
Working directory is the calling process' current working directory;
this may mean different things according to where the srun command is launched.
If within the NFS filesystem, the program will see the same, current, files.
If within a local filesystem (e.g. under /sci-data/),
it will see different files according to the computing node
selected by slurm, so care must be taken.
Unlike srun, the command sbatch takes a script as argument
and schedules the commands in the script for later execution.
By default, sbatch redirects standard output and error to a file of the name
slurm-, where the
Without additional measures, srun will not launch two simultaneous jobs in one node;
subsequent jobs will stall, waiting for the previous one(s) to finish.
This is rather odd since slurm knows that each node has 40 CPUs.
Anyway, since I want many simultaneous jobs to run on each node, I changed the configuration by choosing,
in the SCHEDULING section, SelectType=select/linearOverSubscribe=FORCE:99slurm will take the default value of 4 jobs,
which is largely insufficient for my needs).
top to restrain the number of jobs launched simultaneously
in each node; see also section "perfomance" above.slurm recommends special care with the memory
(should be declared as consumable resource) but the machines composing the cluster
have plenty of RAM so I ignored this recommendation.
apt-get --with-new-pkgs upgrade
apt-mark hold apt-mark showhold
unattended-upgrades performs security updates every morning,
including slurm.
apt does not keep copies of .deb files, see
apt-config dump | grep
Keep-Downloaded-PackagesBinary::apt::APT::Keep-Downloaded-Packages
"true";/etc/apt/apt.conf.d/99-keep-downloads.
Add Dir::Cache::Archives /home/apt-archives;/home/apt-archives instead of /var/cache/apt/archives.
Remember to give enough privileges to _apt user on that directory,
so that everything works properly.
Cristian Barbarosie, 2024.03