Coleções e iterações¶
Coleções¶
No capítulo anterior vimos que uma parte importante de um programa consiste na criação e modificação dos valores de "objetos".
Estes objetos são, na verdade, representados na memória do computador. O acesso a estes objetos é feito à custa de um nome.
A linguagem Python suporta uma variedade de tipos de objetos, dos quais já vimos os números e as strings.
Este capítulo diz respeito a objetos designados genericamente por "coleções".
Definição
Coleções são objetos que contêm mais do que um valor.
As principais coleções usadas em Python são:
- Sequências:
- listas
- strings
- dicionários
Listas¶
a = [2, 4, 3.1415, 'eu aqui', "fim da lista"] print(a)
[2, 4, 3.1415, 'eu aqui', 'fim da lista']
a é uma lista.
As listas são uma dos principais tipos de coleções da linguagem Python.
São usados [] para indicar literalmente os elementos da lista. Por
outro lado, como se pode ver no exemplo, foi atribuído um único nome
(a) para toda a lista.
As listas podem ter elementos de vários tipos e estes elementos podem até ser o resultado de expressões:
a = [19, 14/2, 5.0**3, 'Bom dia'] b = 1 c = [b, b+1, (b+2)**3] print('a =', a) print('c =', c)
a = [19, 7.0, 125.0, 'Bom dia'] c = [1, 2, 27]
Neste exemplo, a lista a contem 3 números e uma string. O valor de
dois dos números é o resultado de uma expressão.
Note-se, também, que na lista c os valores dos elementos são
calculados usando o valor atribuído ao nome b para calcular os
elementos da lista.
Uma propriedade fundamental das listas é que a ordem dos elementos tem significado e uma lista pode ser "indexável" com numeros inteiros.
a = [19, 14/2, 5.0**3, 'Bom dia'] # 0 1 2 3 print(a[0]) print(a[1]) print(a[2]) print(a[3])
19 7.0 125.0 Bom dia
A ordem dos elementos começa a contar do zero e vai até n-1 em que n é o número de elementos da lista.
strings¶
Definição
As strings podem ser entendidas como coleções de caracteres
As strings também têm uma numeração implícita, a contar do zero, sendo também "indexáveis".
s = 'Eu sou uma pequena string' # 0123456789 print(s[0]) print(s[3]) print(s[8])
E s m
Dicionários¶
Definição
Dicionários são associações entre chaves e valores.
d = {'H': 1, 'Li': 3, 'Na': 11, 'K': 19}
Neste exemplo,
'H','Li','Na','K', são as chaves do dicionário
1, 3, 11, 19, são os respetivos valores
Ao contrário das listas e das strings, a ordem dos elementos num dicionário não tem significado mas um dicionário pode ser "indexável" com as chaves:
d = {'H':1, 'Li':3, 'Na':11, 'K':19} print('d =', d) print(d['K']) print(d['Li'])
d = {'H': 1, 'Li': 3, 'Na': 11, 'K': 19}
19
3
Na linguagem Python há três conceitos que são comuns a todas as coleções:
- determinar o número de elementos de uma coleção, com a função
len() - aplicar um conjunto de comandos a todos os elementos de uma coleção,
uma a um, com o comando
for - testar se um valor faz parte de uma coleção, com o operador
in
len() : número de elementos de uma coleção.¶
A função len() pode ser aplicada a qualquer coleção, devolvendo o
número de elementos contidos nessa coleção.
a = [2,4,6,8,10, 'viria o 12', 'e depois o 14'] s = 'Eu sou uma pequena string' d = {'H':1, 'Li':3, 'Na':11, 'K':19} print(len(a)) print(len(s)) print(len(d))
7 25 4
Iteração: comando for¶
Iteração é um conceito geral, que consiste em aplicar um conjunto de instruções ou comandos a cada um dos elementos de uma coleção, um a um.
Em Python é usado o comado for para esse efeito.
a = [2,4,6,8,10, 'viria o 12', 'e depois o 14'] for x in a: print(x)
2 4 6 8 10 viria o 12 e depois o 14
A estrutura geral do comando for é:
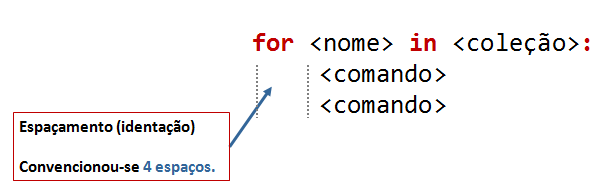
Como se pode ver, o bloco de linhas que é executado e repetido para todos os elementos de uma coleção também é definido pelo alinhamento mais "interior" dessas linhas.
Esta é uma regra geral da linguagem Python: o alinhamento do começo das linhas define blocos.
Vamos ver alguns exemplos da utilização de um comando for:
Problema: mostrar uma tabela de raízes quadradas de 1 a 10
print('tabela de raízes quadradas') a = [1,2,3,4,5,6,7,8,9,10] for x in a: print(x, x**0.5)
tabela de raízes quadradas 1 1.0 2 1.4142135623730951 3 1.7320508075688772 4 2.0 5 2.23606797749979 6 2.449489742783178 7 2.6457513110645907 8 2.8284271247461903 9 3.0 10 3.1622776601683795
# Programa dos anos bissextos sem input anos = [2015, 2014, 2013, 2012, 2000, 1900, 1800] for a in anos: if a % 4 == 0 and not (a % 100 == 0 and not a % 400 == 0): print(a , "é bissexto") else: print(a, "nao é bissexto")
2015 nao é bissexto 2014 nao é bissexto 2013 nao é bissexto 2012 é bissexto 2000 é bissexto 1900 nao é bissexto 1800 nao é bissexto
A iteração de uma string "percorre" os seus caracteres. Os espaços e a pontuação também são considerados caracteres.
s = 'Eu sou uma string' for x in s: print(x)
E u s o u u m a s t r i n g
Finalmente, a iteração de dicionários "percorre" as suas chaves (apenas as chaves).
d = {'H':1, 'Li':3, 'Na':11, 'K':19} for x in d: print(x)
H Li Na K
Mas é fácil usar as chaves para obter uma tabela de chaves-valores:
grupo1 = {'H':1, 'Li':3, 'Na':11, 'K':19} print('elementos do grupo 1') for e in grupo1: print(e, grupo1[e])
elementos do grupo 1 H 1 Li 3 Na 11 K 19
A ordem da iteração das chaves num dicionário é "incerta".
Podemos forçar uma ordem, iterando sobre uma lista com as chaves, na ordem desejada:
grupo1 = {'H':1, 'Li':3, 'Na':11, 'K':19} print('elementos do grupo 1') for e in ['H', 'Li', 'Na', 'K']: print(e, grupo1[e])
elementos do grupo 1 H 1 Li 3 Na 11 K 19
Exemplos de iteração¶
Problema: somar todos os numeros de 1 a 10
nums = [1,2,3,4,5,6,7,8,9,10] s = 0 for i in nums: s = s + i print('a soma de', nums, 'é', s)
a soma de [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] é 55
O papel de s neste exemplo é o de "acumular" a soma de sucessivos
valores obtidos da iteração dos elementos da lista nums.
Inicialmente, antes de começar a iteração (antes do programa entrar no
comando for), s tem o valor 0. Cada vez que "passamos" a um novo
valor i, este é somado ao valor anterior de s. Assim, conseguimos
acumular a soma de todos os i.
É interessante mostrar os valores que estão associados a s ao longo
das iterações. Adaptando o programa anterior com algumas utilizações
dicionais da função print() podemos ver esses valores a mudar para
cada i.
nums = [1,2,3,4,5,6,7,8,9,10] s = 0 for i in nums: print('i =', i) print(' s antes da soma', s) s = s + i print(' s depois da soma', s) print(f'a soma é {s}')
i = 1 s antes da soma 0 s depois da soma 1 i = 2 s antes da soma 1 s depois da soma 3 i = 3 s antes da soma 3 s depois da soma 6 i = 4 s antes da soma 6 s depois da soma 10 i = 5 s antes da soma 10 s depois da soma 15 i = 6 s antes da soma 15 s depois da soma 21 i = 7 s antes da soma 21 s depois da soma 28 i = 8 s antes da soma 28 s depois da soma 36 i = 9 s antes da soma 36 s depois da soma 45 i = 10 s antes da soma 45 s depois da soma 55 a soma é 55
range(): gerador de números inteiros¶
Problema: somar todos os números de 1 a 1000
Desta vez não vamos criar uma lista de números até 1000 explicitamente (e manualmente).
Em vez disso, usamos a função range() que gera números inteiros
consecutivos:
s = 0 for i in range(1, 1001): s = s + i print('a soma dos números de 1 a 1000 é', s)
a soma dos números de 1 a 1000 é 500500
A função range(), que pode ter até 3 argumentos,
range(início, fim, passo), é usada num comando for para gerar uma
sequência de números inteiros, desde um número inteiro inicial (o
início) até um número inteiro final exclusivé (o fim), com um
determinado espaçamento (o passo).
Exemplos:
print('-- range(12) ----------') # acaba em 12 (exclusivé), começa em 0 e percorre de 1 em 1. for i in range(12): print(i)
-- range(12) ---------- 0 1 2 3 4 5 6 7 8 9 10 11
print('-- range(5, 12) ----------') # começa em 5, acaba em 12 (exclusivé) e percorre de 1 em 1. for i in range(5, 12): print(i)
-- range(5, 12) ---------- 5 6 7 8 9 10 11
print('-- range(5, 12, 2) ----------') # começa em 5, acaba em 12 (exclusivé) e percorre de 2 em 2. for i in range(5, 12, 2): print(i)
-- range(5, 12, 2) ---------- 5 7 9 11
Problema: calcular o factorial de 1000
fact = 1 for i in range(1, 1001): fact = fact * i print('o factorial de 100 é', fact)
o factorial de 100 é 402387260077093773543702433923003985719374864210714632543799910429938512398629020592044208486969404800479988610197196058631666872994808558901323829669944590997424504087073759918823627727188732519779505950995276120874975462497043601418278094646496291056393887437886487337119181045825783647849977012476632889835955735432513185323958463075557409114262417474349347553428646576611667797396668820291207379143853719588249808126867838374559731746136085379534524221586593201928090878297308431392844403281231558611036976801357304216168747609675871348312025478589320767169132448426236131412508780208000261683151027341827977704784635868170164365024153691398281264810213092761244896359928705114964975419909342221566832572080821333186116811553615836546984046708975602900950537616475847728421889679646244945160765353408198901385442487984959953319101723355556602139450399736280750137837615307127761926849034352625200015888535147331611702103968175921510907788019393178114194545257223865541461062892187960223838971476088506276862967146674697562911234082439208160153780889893964518263243671616762179168909779911903754031274622289988005195444414282012187361745992642956581746628302955570299024324153181617210465832036786906117260158783520751516284225540265170483304226143974286933061690897968482590125458327168226458066526769958652682272807075781391858178889652208164348344825993266043367660176999612831860788386150279465955131156552036093988180612138558600301435694527224206344631797460594682573103790084024432438465657245014402821885252470935190620929023136493273497565513958720559654228749774011413346962715422845862377387538230483865688976461927383814900140767310446640259899490222221765904339901886018566526485061799702356193897017860040811889729918311021171229845901641921068884387121855646124960798722908519296819372388642614839657382291123125024186649353143970137428531926649875337218940694281434118520158014123344828015051399694290153483077644569099073152433278288269864602789864321139083506217095002597389863554277196742822248757586765752344220207573630569498825087968928162753848863396909959826280956121450994871701244516461260379029309120889086942028510640182154399457156805941872748998094254742173582401063677404595741785160829230135358081840096996372524230560855903700624271243416909004153690105933983835777939410970027753472000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Mais uma vez, temos que acumular os produtos sucessivos. fact tem esse
papel. É análogo a s nos exemplos anteriores. Aqui a diferença é que
estamos a acumular produtos e, por isso, fact tem de ter o valor
inicial de 1 antes de começar a iteração.
Agora um problema semelhante, mas envolvendo strings:
Problema: obter a sequência da cadeia complementar de uma sequência de DNA
Se num programa tivermos uma string contendo uma sequência de um ácido nucleico, então podemos percorrer todas as "bases" da sequência:
seq = 'ATGGTCAAACTTGTTGACTGCAAATGCGTACGT' for b in seq: print(b, end=' ')
A T G G T C A A A C T T G T T G A C T G C A A A T G C G T A C G T
NOTA: o argumento end da função print() permite que, no final, a
mudança de linha seja substituída por outra coisa. Neste exemplo, em vez
de mudar de linha, é mostrado um espaço no final de cada print().
Agora podemos resolver o problema do cálculo da sequência complementar. Parte da estratégia consiste em ir adicionando cada base complementar a uma string de acumulação do resultado, que, inicialmente, está vazia:
seq = 'ATGGTCAAACTTGTTGACTGCAAATGCGTACGT' seqcomp = '' for b in seq: if b == 'A': bcomp = 'T' elif b == 'T': bcomp = 'A' elif b == 'G': bcomp = 'C' else: bcomp = 'G' seqcomp = seqcomp + bcomp print('sequência: ', seq) print('complementar:', seqcomp)
sequência: ATGGTCAAACTTGTTGACTGCAAATGCGTACGT complementar: TACCAGTTTGAACAACTGACGTTTACGCATGCA
Neste exemplo, as letras das bases complementares foram adicionadas, uma
a uma, à string seqcomp.
Antes da iteração com for, seqcomp é criada como uma "string
vazia". As duas aspas consecutivas na atribuição seqcomp = '' definem,
precisamente, uma uma "string vazia".
O programa pode ser modificado elminando os if...elif...elif...else.
A ideia é usar um dicionário que associe cada base à sua base complementar:
seq = 'ATGGTCAAACTTGTTGACTGCAAATGCGTACGT' seqcomp = '' complementares = {'A': 'T', 'T': 'A', 'C': 'G', 'G': 'C'} for b in seq: seqcomp = seqcomp + complementares[b] print('sequência: ', seq) print('complementar:', seqcomp)
sequência: ATGGTCAAACTTGTTGACTGCAAATGCGTACGT complementar: TACCAGTTTGAACAACTGACGTTTACGCATGCA
Sem muito esforço, podemos formatar um pouco a apresentação das duas cadeias, na vertical e pondo em evidência a correspondência entre as bases:
seq = 'ATGGTCAAACTTGTTGACTGCAAATGCGTACGT' complementares = {'A': 'T', 'T': 'A', 'C': 'G', 'G': 'C'} for b in seq: print(b, '-', complementares[b])
A - T T - A G - C G - C T - A C - G A - T A - T A - T C - G T - A T - A G - C T - A T - A G - C A - T C - G T - A G - C C - G A - T A - T A - T T - A G - C C - G G - C T - A A - T C - G G - C T - A
Agora um problema mais elaborado:
converter uma sequência com códigos de uma letra de aminoácidos para códigos de 3 letras, usando um dicionário para a conversão.
trans = {'A': 'Ala', 'C': 'Cys', 'E': 'Glu', 'D': 'Asp', 'G': 'Gly', 'F': 'Phe', 'I': 'Ile', 'H': 'His', 'K': 'Lys', 'M': 'Met', 'L': 'Leu', 'N': 'Asn', 'Q': 'Gln', 'P': 'Pro', 'S': 'Ser', 'R': 'Arg', 'T': 'Thr', 'W': 'Trp', 'V': 'Val', 'Y': 'Tyr'} # Problema: transformar seq1 numa string com os códigos de 3 letras dos aa seq1 = 'ADKLITCWFHHWE' seq3 = '' for aa in seq1: seq3 = seq3 + trans[aa] + '-' print(seq1, 'é o mesmo que ', seq3)
ADKLITCWFHHWE é o mesmo que Ala-Asp-Lys-Leu-Ile-Thr-Cys-Trp-Phe-His-His-Trp-Glu-
in: teste de inclusão¶
Por sua vez, podemos usar o "operador" in como teste de inclusão de um
elemento numa coleção.
nums = [1,2,3,4,5,6,7,8,9,10] if 4 in nums: print(4, 'existe') else: print(4, 'não existe')
4 existe
nums = [1,2,3,4,5,6,7,8,9,10] for n in [1, 4, 7, 20, 40]: if n in nums: print(n, 'existe') else: print(n, 'não existe')
1 existe 4 existe 7 existe 20 não existe 40 não existe
seq = 'ATGGTCAAACTTGTTGACTGCAAATGCGTACGT' if 'U' in seq: print('Existe', 'U') else: print('Não existe', 'U') if 'TGT' in seq: print('Existe', 'TGT') else: print('Não existe', 'TGT')
Não existe U Existe TGT
grupo1 = {'H':1, 'Li':3, 'Na':11, 'K':19} print('Mg' in grupo1)
False
Vamos agora supor que temos o seguinte problema:
Problema: dada a sequência de uma proteína, indicar a presença de lisinas (K)
Percorrer os aminoácidos da sequência é simples, usamos um comando
for. Para testar se estamos na presença de um K, usamos um if:
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for aa in seq: if aa == 'K': print(aa)
K K K
Vamos agora supor que temos uma pequena extensão deste problema:
Problema: dada a sequência de uma proteína, indicar a presença de lisinas (K) e leucinas (L)
Mais uma vez, percorremos os aminoácidos da sequência com for. Para
testar se estamos na presença de um K ou um L, usamos um teste de
inclusão na string "KL"
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for aa in seq: if aa in 'KL': print(aa)
K L L K K
Ou, para visualizar bem a posição das lisinas e leucinas:
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for aa in seq: if aa in 'KL': print(aa, end='') else: print('-', end='')
--K-L-L----------------K----K--
Vamos agora supor que temos um problema muito semelhante:
Problema: dada a sequência de uma proteína, indicar a presença de lisinas (K) e leucinas (L), construíndo uma tabela com posições e códigos K ou L
Podemos usar um "contador" das posições dos aminoácidos, "acumulando" a soma de 1 por letra:
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' i = 0 for aa in seq: if aa in 'KL': print(i, ':', aa) i = i + 1
2 : K 4 : L 6 : L 23 : K 28 : K
É tão frequente a necessidade de percorrer os elementos de uma coleção e, simultaneamente, aceder às posições desses elementos, que a linguagem Python tem uma função para combinar os dois "aos pares":
Função enumerate()¶
Vejamos o que resulta da aplicação da função enumerate() a uma
sequência:
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for x in enumerate(seq): print(x)
(0, 'A') (1, 'D') (2, 'K') (3, 'H') (4, 'L') (5, 'I') (6, 'L') (7, 'T') (8, 'A') (9, 'V') (10, 'G') (11, 'G') (12, 'C') (13, 'W') (14, 'F') (15, 'H') (16, 'V') (17, 'A') (18, 'F') (19, 'W') (20, 'E') (21, 'V') (22, 'E') (23, 'K') (24, 'A') (25, 'G') (26, 'A') (27, 'H') (28, 'K') (29, 'W') (30, 'E')
ou seja, conseguimos percorrer a coleção, mas obtemos pares do tipo (posição, elemento).
O mais interessante é que, no ciclo for com a função
enumerate()podemos usar um par de nomes para nos referirmos
simultaneamente à posição e ao elemento. Isto é chamado desdobramento.
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for (i, a) in enumerate(seq): print(i, ':', a)
0 : A 1 : D 2 : K 3 : H 4 : L 5 : I 6 : L 7 : T 8 : A 9 : V 10 : G 11 : G 12 : C 13 : W 14 : F 15 : H 16 : V 17 : A 18 : F 19 : W 20 : E 21 : V 22 : E 23 : K 24 : A 25 : G 26 : A 27 : H 28 : K 29 : W 30 : E
Na linguagem Python há várias situações em que podemos fazer
desdobramentos de nomes. Um caso que vimos anteriormente é nos comandos
de atribuição de nomes a valores, em que podemos escrever, por exemplo,
a, b, c = 1, 4, 1. Este comando desdobra os nomes para os respetivos
valores, resultando daqui que várias atribuições de nomes podem ser
escritas na mesma linha.
Usando a função enumerate(), o problema de tabelar as posições das
lisinas e argininas pode ser escrito de uma forma mais compacta, sem
usar explicitamente um "contador da posição":
seq = 'ADKHLILTAVGGCWFHVAFWEVEKAGAHKWE' for i, aa in enumerate(seq): if aa in 'KL': print(i, ':', aa)
2 : K 4 : L 6 : L 23 : K 28 : K
Comados for encaixados.¶
Podemos "encaixar" comandos for dentro de outros comandos for. O
efeito é que, para cada iteração de um ciclo for mais "exterior"
percorremos todos os elementos da coleção iterada num comando for mais
"interor".
O melhor será ilustrar com um exemplo clássico, com três níveis de
comandos for:
Problema: gerar os 64 codões do código genético
bases = 'AUGC' for b1 in bases: for b2 in bases: for b3 in bases: c = b1 + b2 + b3 print(c)
AAA AAU AAG AAC AUA AUU AUG AUC AGA AGU AGG AGC ACA ACU ACG ACC UAA UAU UAG UAC UUA UUU UUG UUC UGA UGU UGG UGC UCA UCU UCG UCC GAA GAU GAG GAC GUA GUU GUG GUC GGA GGU GGG GGC GCA GCU GCG GCC CAA CAU CAG CAC CUA CUU CUG CUC CGA CGU CGG CGC CCA CCU CCG CCC
Comando break¶
O comando break permite uma saída prematura de uma iteração: podemos
não chegar ao fim de todos os elementos da coleção que está a ser
iterada se passarmos por um comando break.
Tem utilidade desde que seja utilizado com um if para testar uma
condição.
Problema: obter um esquema das correspondências entre uma sequência de DNA e a sequência complementar, mas parar assim que for encontrado um par C - G.
seq = 'ATGGTTAAACTTGTTGACTGCAAATGCGTACGT' complementares = {'A': 'T', 'T': 'A', 'C': 'G', 'G': 'C'} for b in seq: print(b, '-', complementares[b]) if b == 'C': break
A - T T - A G - C G - C T - A T - A A - T A - T A - T C - G
Comando continue¶
Muito semelhante ao comando break é o comando continue.
Este não força uma saída prematura de uma iteração: o seu efeito é
passar imediatamente para a iteração seguinte, como se voltassemos à
linha imediatamente a seguir ao comando for, mas já para o elemento
seguinte da coleção.
Vejamos com um exemplo:
Problema: obter um esquema das correspondências entre uma sequência de DNA e a sequência complementar. Saltar todos as ligações A - T.
seq = 'ATGGTTAAACTTGTTGACTGCAAATGCGTACGT' complementares = {'A': 'T', 'T': 'A', 'C': 'G', 'G': 'C'} for b in seq: if b in 'AT': continue print(b, '-', complementares[b])
G - C G - C C - G G - C G - C C - G G - C C - G G - C C - G G - C C - G G - C
Comando while¶
O comando while é uma outra forma de repetirmos algumas linhas dentro
de um programa. Nisto é semelhante a um comando for.
No entanto, o comando while está associado ao facto de uma condição
permanecer verdadeira ou não. Enquanto que num comando for percorremos
os elementos de uma coleção, o comando while pode não ter nada a ver
com os elementos de uma coleção.
O comando while é escrito como um bloco de linhas que é executado
enquanto uma condição for verdadeira:
#contagem decrescente count = 10 while count > 0: print(count) count = count - 1 print('kabum!')
10 9 8 7 6 5 4 3 2 1 kabum!
O comando while é pouco usado na linguagem Python. É mais frequente
repetirmos operações enquanto percorremos os elementos de uma coleção.
Por isso, o comando for é mais usado do que o comando while.